Vi skal se på hvordan vi kan analysere vår data med Python. Python er generelt velegnet for å analysere data, og det er en av de mest populære språkene for dette i dag.
Lese CSV
Filene som blir opprettet på Air:Biten sitt SD kort er av typen CSV (Comma Separated Values).
Det er et filformat som inneholder tekst, som representerer en tabell. Tenk som i en Excel fil.
Excel og CSV har tabeller hvor det er et sett med kolonner og rader.
Hver kolonne er en type data (for eksempel temperatur) og hver rad er en måling, eller ett datapunkt.
For å separere kolonner i CSV så brukes det symbolet for komma: ,. Derav navnet Comma Separated Values.
Under ser dere et eksempel fra Air:Bit
Date(DD.MM.YYYY),Time(HH:MM:SS),Lat,Lon,Temperature(°C),Humidity(%),PM25,PM100
01.01.2020,00:00:04,68.3241,18.3241,22.4,22.1,0.0,0.0
01.01.2020,00:00:04,68.3241,18.3241,22.4,22.1,0.0,0.0
01.01.2020,00:00:04,68.3241,18.3241,22.4,22.1,0.0,0.0
01.01.2020,00:00:06,68.3241,18.3241,22.4,22.1,0.0,0.0
01.01.2020,00:00:09,68.3241,18.3241,22.4,22.5,0.0,0.0
01.01.2020,00:00:12,68.3241,18.3241,22.4,22.6,0.0,0.0
01.01.2020,00:00:14,68.3241,18.3241,22.5,22.5,0.0,0.0
01.01.2020,00:00:17,68.3241,18.3241,22.5,22.5,0.0,0.0
01.01.2020,00:00:19,68.3241,18.3241,22.5,22.3,0.0,0.0
01.01.2020,00:00:22,68.3241,18.3241,22.5,22.4,0.0,0.0
01.01.2020,00:00:24,68.3241,18.3241,22.5,22.3,0.0,0.0
Første rad inneholder navnene på alle kolonnene, og hver påfølgende rad har dataen separert med komma. Python er godt egnet for lese denne typen data, og har mange innebygde måter å lese denne på. Vi skal se på to måter her.
Viktig at alt av programmering her må skje på din egen datamaskin og ikke på selve Raspberryen som når vi programmerer Air:Biten. Det kan være lurt å lage seg en mappe på datamaskinen for å legge .csv og .py filer.
Python CSV
Python har en egne csv modul. Den bruker vi gjennom import. Deretter kan vi åpne filen og opprette det som kalles en csv.reader, som henter ut dataen linje for linje til oss.
import csv
with open("2024-01-01.csv", "r") as csv_file:
reader = csv.reader(csv_file, delimiter=",")
next(reader)
for row in reader:
print(row)
Dette programmet vil printe ut en liste per linje, med alle verdiene til filen:
['01.01.2020', '00:00:04', '68.3241', '18.3241', '22.4', '22.1', '0.0', '0.0']
['01.01.2020', '00:00:04', '68.3241', '18.3241', '22.4', '22.1', '0.0', '0.0']
['01.01.2020', '00:00:04', '68.3241', '18.3241', '22.4', '22.1', '0.0', '0.0']
['01.01.2020', '00:00:06', '68.3241', '18.3241', '22.4', '22.1', '0.0', '0.0']
['01.01.2020', '00:00:09', '68.3241', '18.3241', '22.4', '22.5', '0.0', '0.0']
['01.01.2020', '00:00:12', '68.3241', '18.3241', '22.4', '22.6', '0.0', '0.0']
['01.01.2020', '00:00:14', '68.3241', '18.3241', '22.5', '22.5', '0.0', '0.0']
['01.01.2020', '00:00:17', '68.3241', '18.3241', '22.5', '22.5', '0.0', '0.0']
['01.01.2020', '00:00:19', '68.3241', '18.3241', '22.5', '22.3', '0.0', '0.0']
['01.01.2020', '00:00:22', '68.3241', '18.3241', '22.5', '22.4', '0.0', '0.0']
['01.01.2020', '00:00:24', '68.3241', '18.3241', '22.5', '22.3', '0.0', '0.0']
Problemet her er at alle verdiene blir tolket som tekst. Så vi må konvertere alle verdiene i listen. Dette kan gjøre som under:
import csv
data = []
with open(filename, 'r') as fp:
csvfile = csv.reader(fp, delimiter=',')
next(csvfile)
for row in csvfile:
converted_row = []
date, time, lat, lon, temp, hum, pm25, pm100 = row
converted_row.append(datetime.strptime(date + ' ' + time, '%d.%m.%Y %H:%M:%S'))
if "None" in lat:
converted_row.append(None)
converted_row.append(None)
else:
converted_row.append(float(lat))
converted_row.append(float(lon))
converted_row.append(float(temp))
converted_row.append(float(hum))
if pm25 == "None" or pm100 == "None":
continue
converted_row.append(float(pm25))
converted_row.append(float(pm100))
data.append(converted_row)
Nå får vi en liste, hvor hver verdi er den riktige typen den skal være (heltall, dato, flyttall osv). Men vi skal se på en enklere måte å gjøre dette på, hvor vi også kan erstatte manglende data.
Installere biblioteker i Python
For å gjøre dette så skal vi bruke et bibliotek i Python. Python har veldig mange biblioteker, dvs kode andre har skrevet og som vi kan importere og bruke i vår kode. De må gjerne innstalleres før de kan brukes, men heldigvis så er det ganske enkelt innstallere biblioteker/moduler i Python.
Hvis man åpner terminal eller cmd på datamaskinen så får man opp et vindu likt dette:
Hvis vi skriver
python -m pip install
Så kan vi legge inn alle biblioteken vi ønsker på slutten slik:
python -m pip install pandas matplotlib numpy
Dette vil innstallere 3 biblioteker pandas, matplotlib and numpy. Vi kan nå importere disse og bruke de i koden vår. For å lese og plotte data, så skal vi bruke bibliotekene.
Bruke biblioteker
Vi må først importere bibliotekene i toppen av filene våre før vi kan bruke de.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
Når vi har gjort dette, så kan vi modifisere filen som leser .csv dataen vår
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
def read_csv_dataframe(filename):
df = pd.read_csv(filename)
df = df.replace("None", np.nan)
df = df.fillna(method="ffill")
print(df)
Dette leser først dataen vår inn i det som kalles en DataFrame som er en struktur vi bruker i Python for å jobbe med data (minner om en tabell i Excel). Deretter så erstatter vi alle None verdier med np.nan som betyr at det ikke inneholder et tall. Dette gjør vi for at vi skal kunne bruke fillna(method) som fyller inn manglende data (altså der det er np.nan i dataen vår). Metoden som brukes kan vi selv bestemme, her så har vi valgt å bruke method="ffill" som betyr at vi tar siste gyldige måling og fyller inn de samme verdiene.
Når vi nå har lest dataen vår inn i en dataframe, så kan vi plotte med den ved bruk av matplotlib.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
def read_csv_dataframe(filename):
df = pd.read_csv(filename)
df = df.replace("None", np.nan)
df = df.fillna(method="ffill")
df['Time(HH:MM:SS)'] = pd.to_datetime(df['Time(HH:MM:SS)'])
df.plot(x="Time(HH:MM:SS)", y="Humidity(%)")
plt.show()
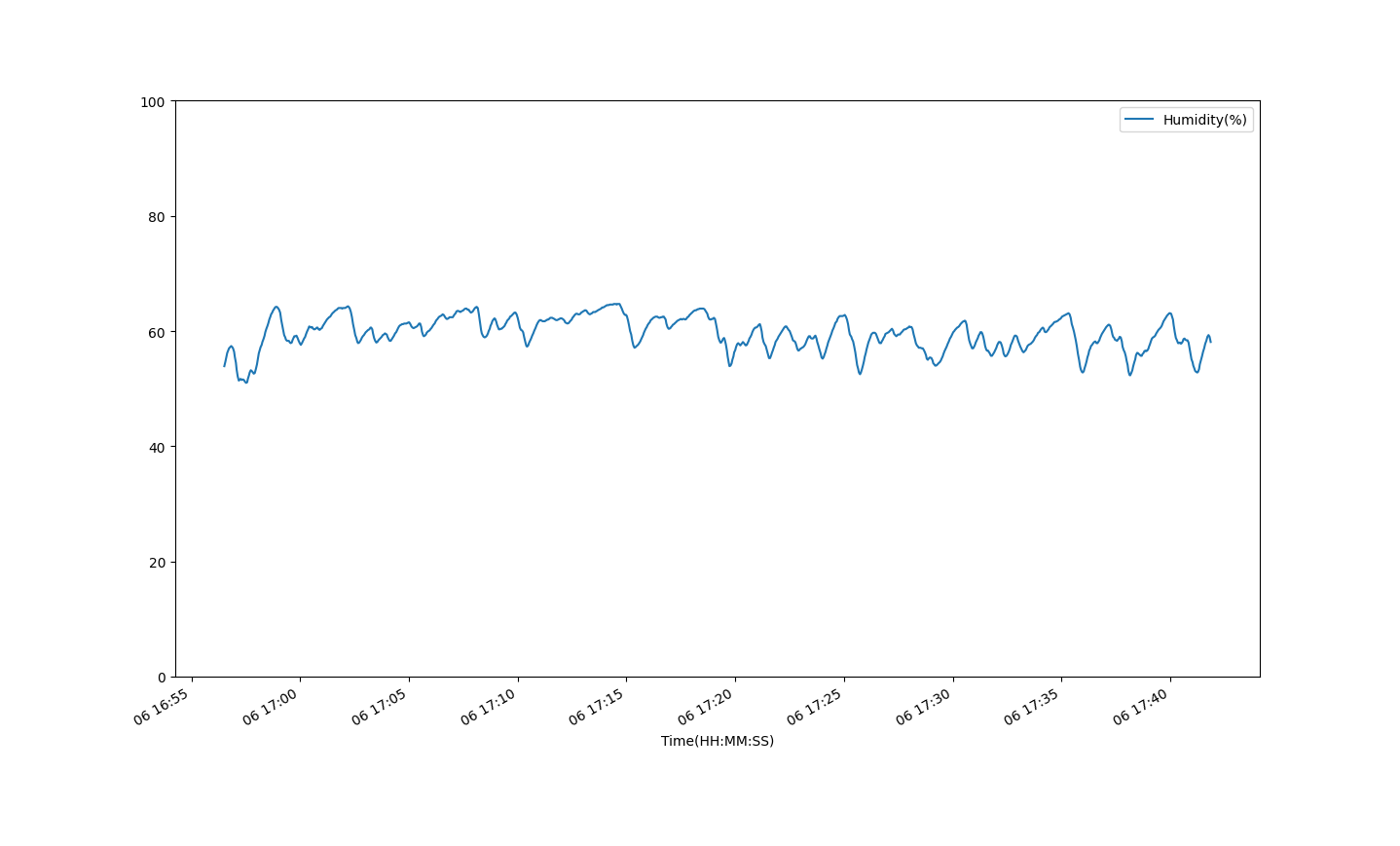
Her har vi plottet tid på x-aksen og fuktighet på y-aksen.
Vi kan også plotte flere variabler i samme plottet.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
def read_csv_dataframe(filename):
df = pd.read_csv(filename)
df = df.replace("None", np.nan)
df = df.fillna(method="ffill")
fig, ax1 = plt.subplots()
ax2 = ax1.twinx()
df.plot(x="Time(HH:MM:SS)", y=["Humidity(%)"], kind="line", ax=ax2, color="blue")
ax2.set_ylabel("Humidity")
df.plot(x="Time(HH:MM:SS)", y=["Temperature(°C)"], kind="line", ax=ax1, color="orange")
ax1.set_ylabel("Temperature")
ax1.set_ylim((-9, -5))
ax1.legend(loc="upper left")
ax2.set_ylim((0,100))
ax2.legend(loc="upper right")
plt.show()
Her ser vi at kind="line" styrer typen plot (det finnes mange, f eks line, bar, hist, box, kde og flere). Vi plotter de også på hver sin akse ax1 og ax2 slik at de har hver sin y-akse med forskjellige verdier. X-aksen vår er fortsatt tid.
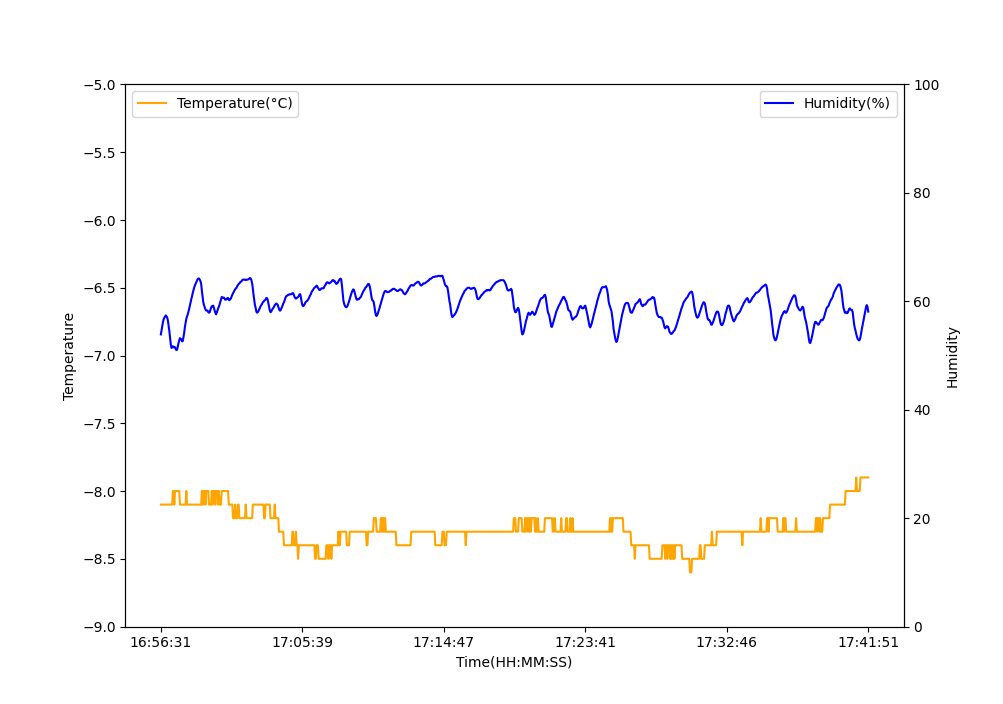
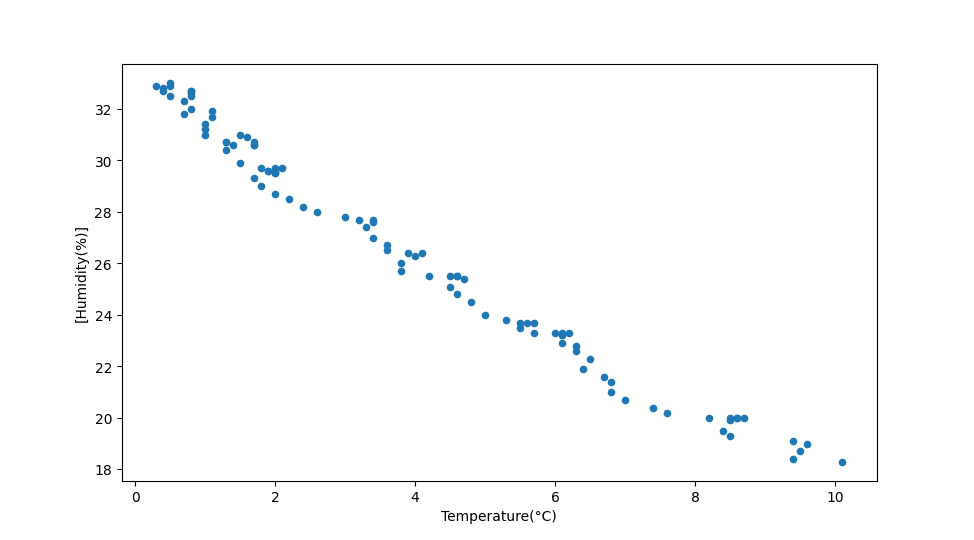
Det er også mulig å plotte to variabler mot hverandre uten å bruke tid. Men da gir det kanskje ikke mening å bruke linjer lengre (da dataen kan bevege seg litt over alt i plottet). Her bruker vi scatter-plots som lager en prikk per datapunkt.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
def read_csv_dataframe(filename):
df = pd.read_csv(filename)
df = df.replace("None", np.nan)
df = df.fillna(method="ffill")
df.plot(x="Temperature(°C)", y=["Humidity(%)"], kind="scatter")
plt.show()
Kalle funksjoner
I de forrige eksemplene så har vi laget en funksjon som heter read_csv_dataframe, men for å faktisk bruke denne funksjonen så må vi kalle på den. Nederst i filen så bruker jeg følgende kode for å kalle på funksjonen for å lese en fil som heter 2023-12-13.csv
if __name__ == "__main__":
read_csv_dataframe("2023-12-13.csv")
Her er det viktig at man bytter ut 2023-12-13.csv med det filnavnet man ønsker å lese. Filen som koden ligger i og .csv filen må ligge ved siden av hverandre for at dette skal fungere.